Достаточно часто встречаются случаи, когда стандартные имена переменных в выгруженном массиве по каким-то причинам не подходят. Например, заказчик хочет, чтобы переменные совпадали с вопросами анкеты, предоставленной для программирования, или с его макетом массива.
В большинстве случаев можно просто указать имя желаемой переменной в поле Шаблон редактора вопроса:
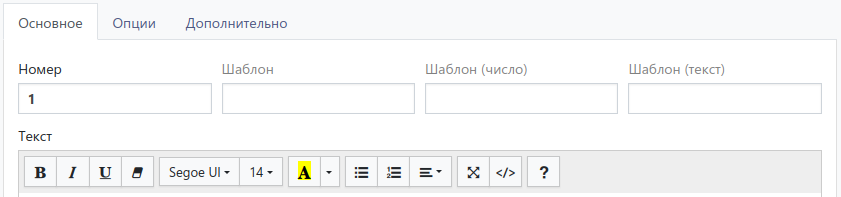
Например, если вопрос Q1 в массиве должен называться FD6, то так и пишем в поле Шаблон.
Имена переменных не влияют на сохранённые интервью и их можно менять в любой момент времени.
Чтобы массив выгрузился корректно, в свойствах анкеты должен стоять флаг Автоматически формировать имена переменных в массиве:
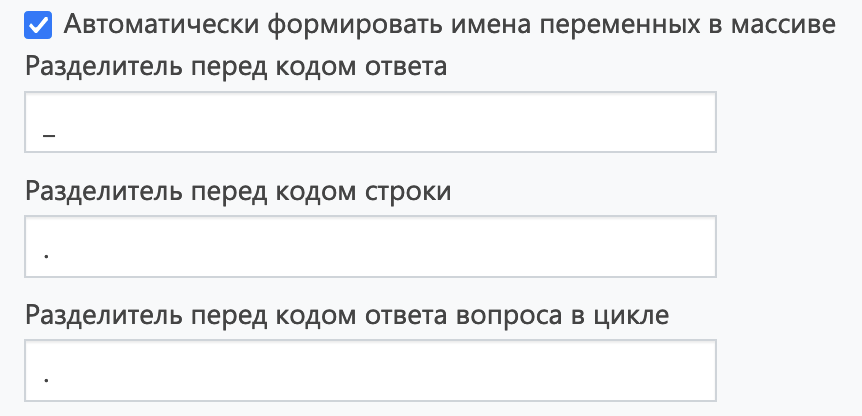
При необходимости вы можете изменить или совсем убрать разделители между номером вопроса и кодами ответов или строк таблицы в соответствующих полях. Они используются, если ответы вопроса занимают больше одной колонки в массиве.
Параметры для всех новых анкет можно указать в настройках по умолчанию.
Помимо этого при прописывании имён переменных важно соблюдать требования SPSS к ним.
Важные правила
- Имя каждой переменной должно быть уникальным; дублирование недопустимо. Регистр значения не имеет: VarName, varname, VARNAME – одно и то же имя.
- Имя может содержать как английские, так и русские буквы, цифры и символы
_.@#$Символ «минус» (-) автоматически заменяется подчёркиванием. Пробелы недопустимы. - Максимальная длина имени – 64 байта (64 английские буквы или 32 русские).
- Переменная должна начинаться с буквы и не должна заканчиваться точкой (
.) - В качестве имени нельзя использовать зарезервированные SPSS слова (ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH), а также стандартные имена переменных SURVEYSTUDIO, которые можно посмотреть здесь, если итоговое имя переменной содержит только служебное слово. Например,
ALL_12илиALLOможно, простоALLнельзя.
Их несоблюдение приведёт к ошибкам и невозможности выгрузить массив в любом формате файла.
Что делать, если автоматически формируемые имена не подходят в моём случае?
Тогда нужно отключить в анкете автоматическое формирование, и понять принцип создания массива, а также запомнить доступные в SURVEYSTUDIO подстановки кодов ответов и строк таблицы для формирования имён переменных полностью вручную. Это просто.
Для вопроса с одним ответом в массив добавляется одна колонка. С несколькими - столько колонок, сколько всего вариантов ответа в вопросе. С уважением, Капитан Очевидность :)
То же самое для табличных вопросов: сколько есть строк - столько колонок. А если таблица с несколькими ответами - для каждой строки добавляются колонки для всех вариантов ответа. Ну а если у ответов или строк есть дополнительные числовые и текстовые поля - ещё колонки в массиве.
Если выгрузить макет массива со стандартными именами, то он выглядит примерно так:

Здесь видно, что в Q1 и Q2 предполагается один ответ. В Q3 - тоже один, но у ответа с кодом 3 есть числовое поле. В Q4 - пять ответов, это либо вопрос с множественным выбором, либо табличный, и у ответа или строки с кодом 4 - текстовое поле.
И вот, допустим, в этом массиве надо букву Q заменить на S без использования автоматического формирования имён переменных.
Где указывать имена?
Как вы видели выше, в свойствах вопроса, справа от его номера, есть 3 поля для имён переменных:
- Второе поле - переменная вопроса,
- третье - переменная числового поля,
- четвёртое - текстового поля.
Что будет в массиве, если во втором поле вопроса с несколькими ответами написать S35? Вопрос с подвохом :) Массива не будет, потому что колонку каждого ответа система попытается назвать S35, S35, S35…, что недопустимо. Тут-то и нужны подстановки.
Доступные подстановки
- {1} - код варианта ответа или его порядковый номер, если включён режим категориального кодирования ответов,
- {2} - код строки таблицы,
- {3} - код или псевдоним варианта ответа, для которого создаётся вопрос - если он находится внутри цикла,
- {0} - номер вопроса SURVEYSTUDIO (для экзотических случаев).
Если перевести на русский язык, то, например {2}, буквально означает: «подставить на это самое место код строки таблицы».
Примеры
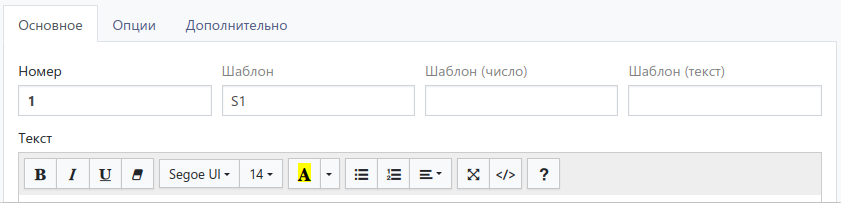
Если вопрос предполагает один ответ, то во втором поле нужно просто указать желаемое имя. Для Q1 массива выше:
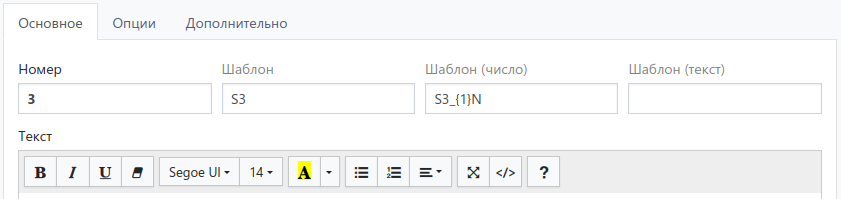
А если у одного из ответов есть числовое поле (в Q3):
Для вопроса с множественным выбором, и у ответов которого есть текстовые поля (в Q4):
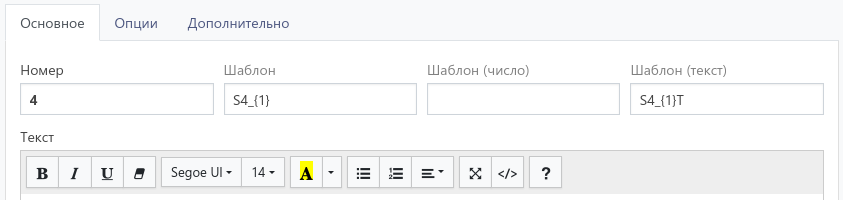
В итоге получится:
![]()
Хочу то же картинкой
На примере некого Q10 показано, какие подстановки к имени A25 следует добавить в различных случаях: https://coggle.it/diagram/YEiHIdWHwvE_MPx8/t/q10/0a675152e0204e4b63120ff98c7d41eff87e41a299c53a4a270a9be7ce6ef5b9
О чём ещё стоит знать?
Для необычных случаев имена переменных можно прописать у ответа или строки таблицы:

Как видно, здесь полей больше, чем у вопроса.
- Второе поле - псевдоним (если в массиве вместо кода из первого поля нужно что-то другое),
- третье - переменная ответа/строки,
- четвёртое - переменная числового поля,
- пятое - текстового поля.